Today is one of the happiest days of my life because, for the first time, I saw the real power of python and the Natural Language Took kit library.
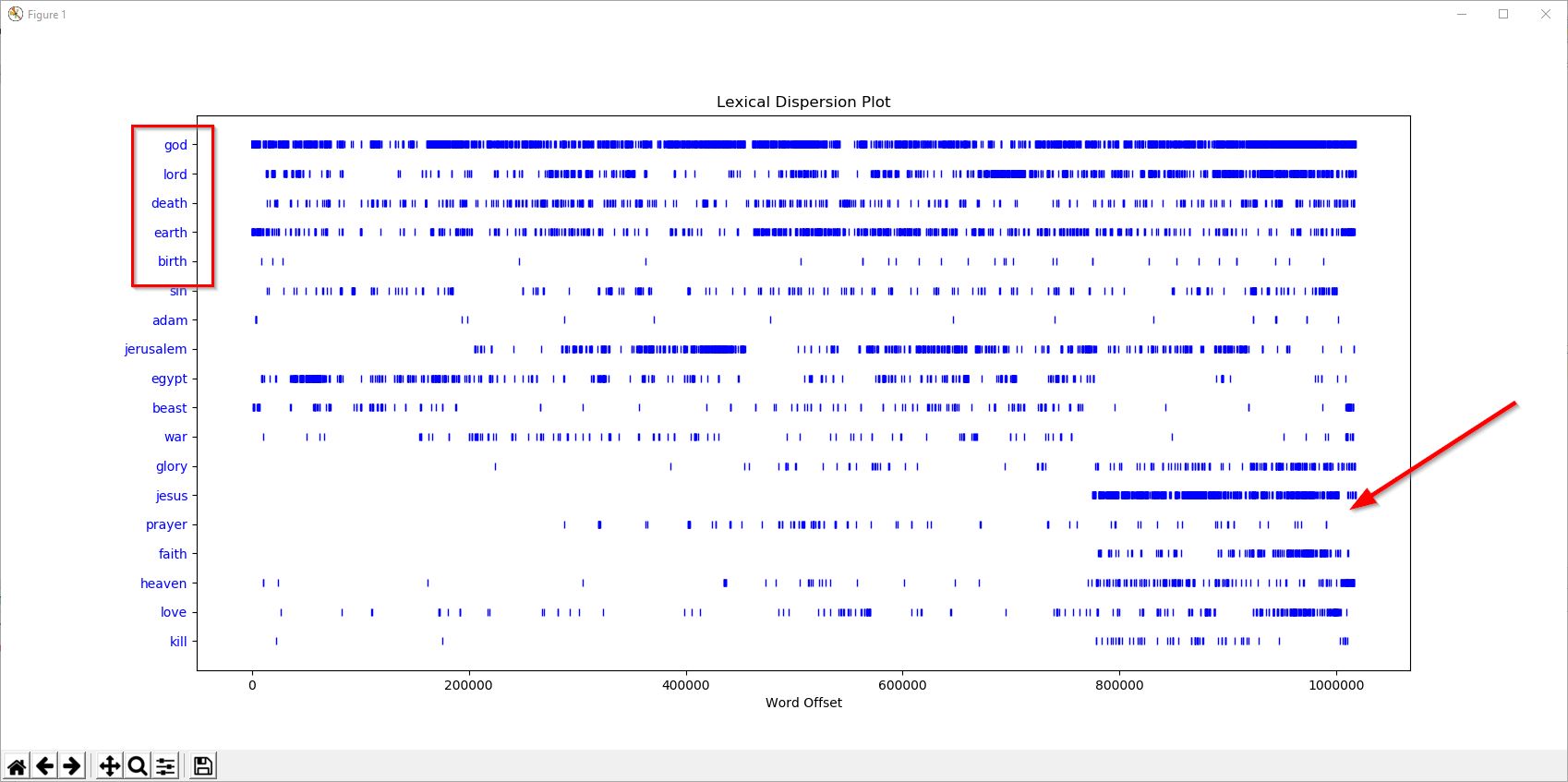
I had downloaded the text version of bible yesterday and using that as input and the following lines of code ( source code is after the picture), I was able to see, how different words were spread across the entire Bible. Think about it, there must have been a reason certain words were used in the beginning of the Bible and some at the end, and some words completely omitted from these initial texts( words like, Jesus and prayer, hardly appear in the initial texts ) .
And also considering that the texts in Bible were added in a chronological manner, we get a basic idea, about the thought process and the concepts that were formed in the author’s mind, when the bible was written ( over a period of time ) We get to see, how certain words are consistently used through the texts ( for example the words ‘God’, ‘Earth’ etc ) and how Bible reflected what people spoke about for a period of 4,000 years !
( I have highlighted some patterns below )
Source code
import matplotlib.pyplot as pltimport nltknltk.data.path.append("E:\\dev\\lib\\python\\nltk_data")f=open(r"F:\resources\bible\ylt\ylt.txt",'rU')raw=f.read()tokens = nltk.word_tokenize(raw.lower())text = nltk.Text(tokens)text.dispersion_plot(["god", "lord", "death" ,"earth", "birth", "sin", "adam", "jerusalem" , "egypt" , "beast" , "war","glory", "jesus" , "prayer", "faith", "heaven" , "love","kill" ])